ZooKeeper 是一个开源的分布式协调服务,由雅虎创建,是 Google Chubby 的开源实现。 分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协 调/通知、集群管理、Master 选举、配置维护,名字服务、分布式同步、分布式锁和分布式队列 等功能。
Zookeeper架构
集群架构
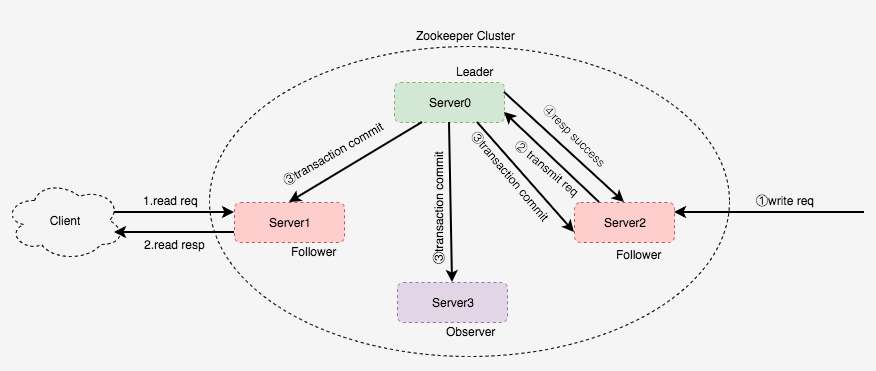 zookeeper可以实现单机部署和集群部署,其多作为集群部署提高系统的可靠性。
系统中分为领导者(Leader)、追随者(Follower)、观察者(Observer)角色。其每个角色的职责如下:
zookeeper可以实现单机部署和集群部署,其多作为集群部署提高系统的可靠性。
系统中分为领导者(Leader)、追随者(Follower)、观察者(Observer)角色。其每个角色的职责如下:
-
Leader
集群中各个节点属于均等状态,都可能成为领导者,集群上线后,首先通过Zab算法平等竞争Leader。竞争成功者成为集群Leader.集群中只能存在唯一的Leader,当集群中Leader宕机或者与绝大多数的Follower失去连接后,集群重新进入Leader选举过程。选举成为Leader的节点主要工作有: - 处理客户端写请求
- 处理与Follower的心跳检测
- 处理与Follower和Observer的数据同步
-
参与集群Leader选举和投票
-
Observer
集群中Observer不参与集群Leader的选举和投票,通过配置文件设置某个节点为Observer,其只对外提供读服务,通过增加Observer提高系统的可读性能,观察者作为集群中的节点其主要职责是:- 与Leader数据同步
- 处理客户端的读服务
-
Follower
集群中任何没有竞争成为Leader的节点都是作为Follower(除Observer),其主要职责为:- 参与集群Leader的竞争与投票
- 处理客户端读请求
- 与Leader数据同步
-
工作流程
- 读取过程
集群中节点都可以处理客户端的读请求,(Leader节点是否处理读请求可以通过配置文件配置),当节点收到客户端读请求后,则直接通过读取本地的数据返回给客户端。 - 写入过程
如上各种角色职责介绍,集群中只有Leader处理写请求,如setData,当集群中非Leader节点接收到客户端写请求,其首先将该请求转发给Leader节点,Leader节点通过广播协议,实现集群各个节点的分布式事务原子写入。分布式事务写入采用二阶段提交原理
Zookeeper逻辑架构
内存结构
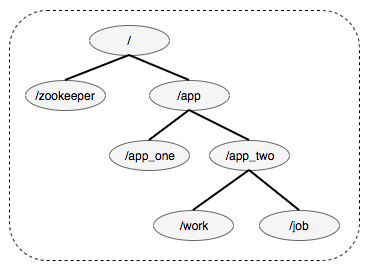
如图所示,Zookeeper内存结构采用类似于Linux文件系统树状结构,每个节点具有父节点和子节点。每个节点维护stat元数据信息以及Data数据信息,stat记录节点状态信息以及版本等信息,Data维护节点下存储的数据信息。
系统中节点分为持久节点和临时节点、顺序节点和非顺序节点。
| 名称 | 含义 |
|---|---|
| 临时节点 | 客户端与服务端之间通过会话连接,会话断开节点则消失 |
| 持久节点 | 会话断开,节点不消失 |
| 顺序节点 | 可以多次创建一个节点,节点名称后顺序添加序号,如 job-00001,job-00002 |
| 非顺序节点 | 唯一存在节点,多次创建会报错 |
上述类型其两两组合成四种类型:持久顺序节点、持久临时节点、临时顺序节点、临时非顺序节点。通过创建不同的节点类型可以实现不同的功能(见下一节)。
数据持久化
Zookeeper基于内存的结构,其DataTree存储在内存中,为保证数据的可靠和不丢失,其持久化采用快照(Snapshot)和事务日志方式。
其快照文件和事务日志文件存储在配置文件中dataDir参数指定的目录下。快照文件以Snapshot.xxxxx形式命名,其中xxxx为该文件中最小事务ID(ZXID),同样,事务日志以log.xxxxxx方式命名,其xxxxx为事务日志中最小事务ID(ZXID),因此根据ZXID可以快速定位到事务日志文件的位置。此外,为避免事务日志文件的读写性能,事务日志文件采用预分配的方式,即在创建日志文件时预先分配固定大小的磁盘(默认为64M)并且以「/0」填充。
快照文件并不是实时写入,而是以后台线程定时写入,因此在写入快照文件时,可能会存在客户端写请求更新内存中DataTree,因此快照文件又称为Fuzzy快照,在系统宕机后,通过快照文件的事务ID信息以及事务日志中的事务ID,通过重做两者之间的差值可以恢复到最新数据。
Zookeeper典型应用场景
选主
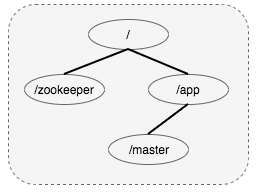
如图所示,主库在/app路径下创建临时非顺序节点,备库在/app/master创建watcher监视点,当主库宕机时,则/app/master节点消失,此时备库接收到watcher时间,备库创建/master节点成为主库,达到主库的无缝切换。
服务注册与发现
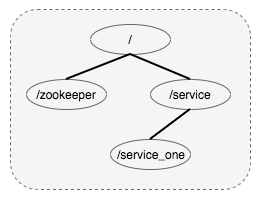 服务注册方在
服务注册方在/service节点下创建临时节点,存储服务相关信息,客户端通过查询/service子节点信息发现服务。
DNS动态域名解析
在/domain节点下创建域名节点/service.baidu.com,在此节点下创建临时节点/server0、/server2、/server1节点存储IP信息,接收到客户端解析域名请求后,获取/domian/service.baidu.com下IP地址信息,以负载均衡策略返回一个IP信息给客户端。
分布式锁
在/lock节点下创建临时节点/lock/locker,创建成功则表示获取到锁,否则获取锁失败,则在/lock节点注册watcher监视点,当收到消息时再次尝试创建/locker节点,执行上述过程。
分布式队列
客户端在/queue节点下创建顺序临时节点,然后getChildren获取/queue子节点信息,通过比对子节点中序号最小是否等于自己创建的节点,如果相等则表名可以出队列,否则注册watcher监视点,/queue节点变化时获取通知再次获取/queue子节点信息执行上述过程。
=======
Zookeeper架构
集群架构
zookeeper可以实现单机部署和集群部署,其多作为集群部署提高系统的可靠性。
系统中分为领导者(Leader)、追随者(Follower)、观察者(Observer)角色。其每个角色的职责如下:
- Leader
集群中各个节点属于均等状态,都可能成为领导者,集群上线后,首先通过Zab算法平等竞争Leader。竞争成功者成为集群Leader.集群中只能存在唯一的Leader,当集群中Leader宕机或者与绝大多数的Follower失去连接后,集群重新进入Leader选举过程。选举成为Leader的节点主要工作有: - 处理客户端写请求
- 处理与Follower的心跳检测
- 处理与Follower和Observer的数据同步
-
参与集群Leader选举和投票
- Observer
集群中Observer不参与集群Leader的选举和投票,通过配置文件设置某个节点为Observer,其只对外提供读服务,通过增加Observer提高系统的可读性能,观察者作为集群中的节点其主要职责是:- 与Leader数据同步
- 处理客户端的读服务
- Follower
集群中任何没有竞争成为Leader的节点都是作为Follower(除Observer),其主要职责为:- 参与集群Leader的竞争与投票
- 处理客户端读请求
- 与Leader数据同步
工作流程
- 读取过程
集群中节点都可以处理客户端的读请求,(Leader节点是否处理读请求可以通过配置文件配置),当节点收到客户端读请求后,则直接通过读取本地的数据返回给客户端。 - 写入过程
如上各种角色职责介绍,集群中只有Leader处理写请求,如setData,当集群中非Leader节点接收到客户端写请求,其首先将该请求转发给Leader节点,Leader节点通过广播协议,实现集群各个节点的分布式事务原子写入。分布式事务写入采用二阶段提交原理
Zookeeper逻辑架构
内存结构
如图所示,Zookeeper内存结构采用类似于Linux文件系统树状结构,每个节点具有父节点和子节点。每个节点维护stat元数据信息以及Data数据信息,stat记录节点状态信息以及版本等信息,Data维护节点下存储的数据信息。
系统中节点分为持久节点和临时节点、顺序节点和非顺序节点。
| 名称 | 含义 |
|---|---|
| 临时节点 | 客户端与服务端之间通过会话连接,会话断开节点则消失 |
| 持久节点 | 会话断开,节点不消失 |
| 顺序节点 | 可以多次创建一个节点,节点名称后顺序添加序号,如 job-00001,job-00002 |
| 非顺序节点 | 唯一存在节点,多次创建会报错 |
上述类型其两两组合成四种类型:持久顺序节点、持久临时节点、临时顺序节点、临时非顺序节点。通过创建不同的节点类型可以实现不同的功能(见下一节)。
数据持久化
Zookeeper基于内存的结构,其DataTree存储在内存中,为保证数据的可靠和不丢失,其持久化采用快照(Snapshot)和事务日志方式。
其快照文件和事务日志文件存储在配置文件中dataDir参数指定的目录下。快照文件以Snapshot.xxxxx形式命名,其中xxxx为该文件中最小事务ID(ZXID),同样,事务日志以log.xxxxxx方式命名,其xxxxx为事务日志中最小事务ID(ZXID),因此根据ZXID可以快速定位到事务日志文件的位置。此外,为避免事务日志文件的读写性能,事务日志文件采用预分配的方式,即在创建日志文件时预先分配固定大小的磁盘(默认为64M)并且以「/0」填充。
快照文件并不是实时写入,而是以后台线程定时写入,因此在写入快照文件时,可能会存在客户端写请求更新内存中DataTree,因此快照文件又称为Fuzzy快照,在系统宕机后,通过快照文件的事务ID信息以及事务日志中的事务ID,通过重做两者之间的差值可以恢复到最新数据。
Zookeeper典型应用场景
选主
如图所示,主库在/app路径下创建临时非顺序节点,备库在/app/master创建watcher监视点,当主库宕机时,则/app/master节点消失,此时备库接收到watcher时间,备库创建/master节点成为主库,达到主库的无缝切换。
服务注册与发现
服务注册方在/service节点下创建临时节点,存储服务相关信息,客户端通过查询/service子节点信息发现服务。
DNS动态域名解析
在/domain节点下创建域名节点/service.baidu.com,在此节点下创建临时节点/server0、/server2、/server1节点存储IP信息,接收到客户端解析域名请求后,获取/domian/service.baidu.com下IP地址信息,以负载均衡策略返回一个IP信息给客户端。
分布式锁
在/lock节点下创建临时节点/lock/locker,创建成功则表示获取到锁,否则获取锁失败,则在/lock节点注册watcher监视点,当收到消息时再次尝试创建/locker节点,执行上述过程。
分布式队列
客户端在/queue节点下创建顺序临时节点,然后getChildren获取/queue子节点信息,通过比对子节点中序号最小是否等于自己创建的节点,如果相等则表名可以出队列,否则注册watcher监视点,/queue节点变化时获取通知再次获取/queue子节点信息执行上述过程。
e0c706e4163ccfa930a95037750b1fb38cf564e1