MySQL是一个开放源代码的关系数据库管理系统。原开发者为瑞典的MySQL AB公司,最早是在2001年MySQL3.23进入到管理员的视野并在之后获得广泛的应用。 2008年MySQL公司被Sun公司收购并发布了首个收购之后的版本MySQL5.1,该版本引入分区、基于行复制以及plugin API。移除了原有的BerkeyDB引擎,同时,Oracle收购InnoDB Oy发布了InnoDB plugin,这后来发展成为著名的InnoDB引擎。2010年Oracle收购Sun公司,这也使得MySQL归入Oracle门下,之后Oracle发布了收购以后的首个版本5.5,该版本主要改善集中在性能、扩展性、复制、分区以及对windows的支持。目前版本已发展到5.7。 和其它数据库相比,MySQL有点与众不同,它的架构可以在多种不同场景中应用并发挥良好作用。主要体现在存储引擎的架构上,插件式的存储引擎架构将查询处理和其它的系统任务以及数据的存储提取相分离。这种架构可以根据业务的需求和实际需要选择合适的存储引擎。
1.引言
在介绍数据库架构之前先了解两个概念:
实例:mysql是单进程多线程架构,实例就是服务端的一个进程,是由后台线程以及一个共享内存区组成,对数据库的操作需要通过实例完成。 数据库:是物理操作系统中文件或者其他形式文件类型的集合,表现为操作系统中frm、ibd等文件,是静态概念。 一个实例可以操作多个数据库,
1.数据库架构
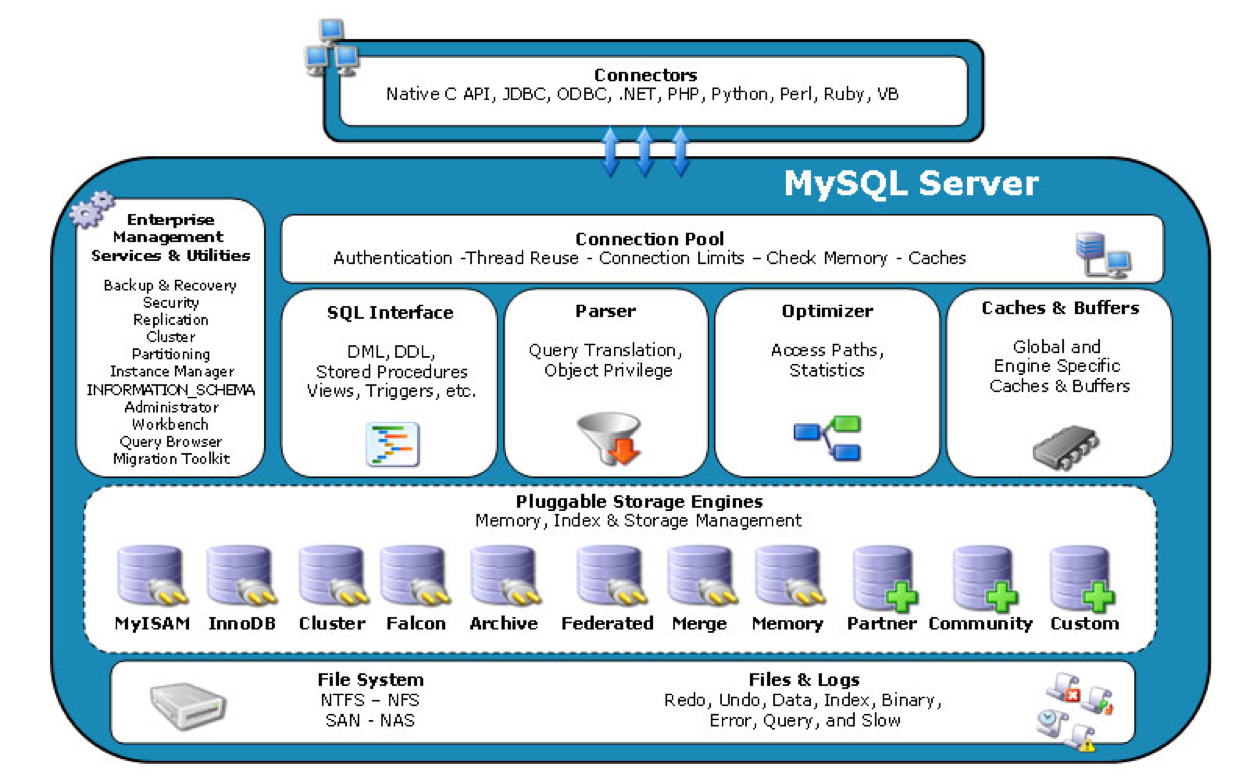
- Connection Pool
最上层是一些客户端和连接服务,包含本地sock通信和大多数基于客户端/服务端工具实现的类似于tcp/ip的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
- Parser
第二层架构主要完成大多少的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化及部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如过程、函数等。在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化如确定查询表的顺序,是否利用索引等,最后生成相应的执行操作。如果是select语句,服务器还会查询内部的缓存。如果缓存空间足够大,这样在解决大量读操作的环境中能够很好的提升系统的性能。
- Engines
存储引擎层,存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取。事务机制实现在引擎
- File System
数据存储层,主要是将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互。
2.MySQL目录结构
- BUILD: 内含在各个平台、各种编译器下进行编译的脚本。如compile-pentium-debug表示在pentium架构上进行调试编译的脚本。
- client: 客户端工具,如mysql,mysqladmin之类。
- cmd-line-utils: readline,libedit工具。
- config: 给aclocal使用的配置文件。
- dbug: 提供一些调试用的宏定义。
- Docs: MySQL在不同平台下的参考手册
- extra: 提供innochecksum,resolveip等额外的小工具。
- include: 包含的头文件
- libmysql: 库文件,生产libmysqlclient.so。
- libmysql_r: 线程安全的库文件,生成libmysqlclient_r.so。
- libmysqld: 嵌入式MySQL Server库.
- libservices: 5.5.0中新加的目录,实现了打印功能。
- man: 适合man命令查看的帮助文件。
- mysql-test: mysqld的测试工具套件。
- mysys: 为实现跨平台,MySQL自己实现了一套常用的数据结构和算法,如string, hash等。还包含一些底层函数的跨平台封装,一般以my_开头。
- netware: 在netware平台上进行编译时需要的工具和库。
- plugin: MySQL 5.1开始支持一个插件式API接口,不需要重启mysqld即可动态载入插件,FullText就是一个例子。
- pstack: GNU异步栈追踪工具。
- regex: 正则表达式实现(来自多伦多大学Henry Spencer大牛的源码)。
- scripts: 提供脚本工具,如mysql_install_db/mysqld_safe等。
- server-tools: 包含instance_manager子目录,负责实例的本地和远程管理。
- sql: MySQL Server主要代码,将会生成mysqld文件。
- sql-bench: 一些基准测试代码代码,主要是Perl程序(虽然后缀是sh)。
- sql-common: 存放部分服务器端和客户端都会用到的代码,有些地方的同名文件是这里lin过去的。
- storage: 存储引擎所在目录。
- strings: string库,包含很多字符串处理的函数。
- support-files: my.cnf示例配置文件及编译所需的一些工具。
- tests: 测试文件所在目录。
- unittest: 单元测试文件。
- vio: 虚拟io系统,是对network io的封装,把不同的协议封装成统一的IO函数。
- win: 在windows平台编译所需的文件和一些说明。
- zlib: zlib算法库(GNU)
3.InnoDB目录结构
- btr: B+树的实现
- buf: 缓冲池的实现,包括LRU算法,Flush刷新算法等
- dict: InnoDB内存数据字典的实现
- dyn: InnoDB动态数组的实现
- fil: InnoDB文件数据结构以及对于文件的一些操作
- fsp: 对InnoDB物理文件的管理,如页/区/段等(即File Space)
- ha: 哈希算法的实现
- handler: 继承与MySQL的handler,实现handler API与Server交互
- ibuf: 插入缓冲(Insert Buffer)的实现
- include: InnoDB所有头文件都放在这个目录,是查找结构定义的最佳地点
- lock: InnoDB的锁实现及三种锁算法实现
- log: 日志缓冲(Log Buffer)和重做日志组(Redo Log)的实现
- mem: 辅助缓冲池(Additional Memory Pool)的实现,用来申请一些内部数据结构的内存
- mtr: 事务的底层实现(日志,缓冲)
- os: 封装一些对于操作系统的操作
- page: 页的实现,研究InnoDB文件结构,这个目录至关重要
- pars: 重载部分MySQL的SQL Parser(有待商榷)
- que: Query graph,基本上没啥用
- read: 读取游标的实现
- rem: 行管理操作(比较操作,打印等)
- row: 对于各种类型行数据操作的实现
- srv: InnoDB后台线程,启动服务,Master Thread,SQL队列等
- sync: InnoDB互斥变量(Mutex)的实现,基本同步机制
- thr: InnoDB封装的可移植线程库
- trx: 事务的实现
- usr: Session管理
- ut: 各种通用小工具
4.核心类库
- THD: 线程类
- Item: Item类(查询条目,函数,WHERE,ORDER,GROUP,ON子句等)
- TABLE: 表描述符
- TABEL_LIST: JOIN操作描述符
- Field: 列数据类型及属性定义
- LEX: 语法树
- Protocol: 通讯协议
- NET: 网络描述符
- handler: 存储引擎接口
5.客户端与服务端交互
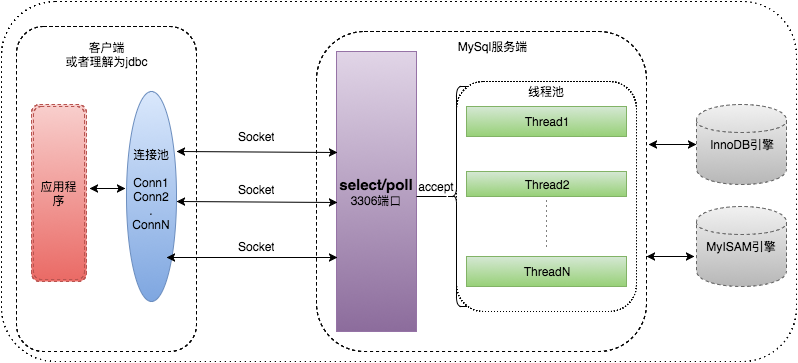
- 客户端:各种语言层面jdbc驱动可以理解为客户端,客户端通过连接池与服务器进行交互。
- 服务端:服务端采用select/poll IO多路复用机制实现客户端的连接,后端采用线程池处理与客户端的连接;当接收到客户端连接,服务器首先会查询是否有空闲线程,如果有则获得线程处理与客户端的交互,否则验证当前线程数是否大于max_connections,如果小于max_connections,则创建线程,否则丢弃连接。
注: max_connections是不是越大越好?受哪些因素的影响?
1.系统层面文件描述符的个数:系统默认可以打开最大文件描述符数为 65535; 2.select模型:select底层采用数组方式监听socket,默认监听数目为1024,可以通过配置文件修改个数,最大不超过65535,且随着数目增加,服务端性能变差。 3.服务端CPU及内存等硬件情况:服务端采用线程池处理与客户端的连接,线程池中数目大小受限于内存。