前言
本文从操作系统谈起,简单介绍操作系统基本知识,引出进程、线程调度的基本原理和基本模型,然后从0到1设计Golang调度器,通过方案的逐步演进升级,可以了解到GPM模型设计理念。 阅读本文会了解到线程模型、线程调度,并最终理解Golang为什么设计为GPM模型,并通过简要runtime代码分析,验证在GPM模型推演过程中各种问题设想以及解决方案。
操作系统基础知识
本章节介绍操作系统基本知识,如什么是内核态与用户态?为什么要有内核态和用户态?用户态和内核态区别? 从而引申出线程模型,对相关知识熟悉的同学可以跳过本章节。
维基给操作系统的定义是一组主管并控制计算机操作、运用和运行硬件、软件资源和提供公共服务来组织用户交互的相互关联的系统软件程序。 去掉定语可以简单理解 :操作系统(operation system,简称OS)是系统软件程序。 进一步可以理解:操作系统也是一种程序、代码,其介于计算机硬件,和上层软件之间的一种软件。 其核心职能无非五个方面:进程、存储、设备、文件、作业管理。
什么是用户态和内核态?
大前提:软件程序运行需要资源(存储)
小前提:操作系统是软件
结论: 操作系统运行需要资源
介于上述三段式结论,
- 操作系统运行时使用的存储资源叫内核态
- 用户(上层软件)运行时使用的存储资源叫用户态。
对于32位系统而言,其最大寻址空间为 2^32次方=4G内存。 linux系统内核态和用户态占比1:3,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。 windows系统内核态和用户态占比2:2 (难道这就是windows比linux卡顿的原因?)
为什么要分为内核态和用户态?两者可以共用么?
内核态和用户态实现了权限隔离。 试想,如果上层程序可以随意访问、修改操作系统运行内存,恶意行为或者bug等异常操作可能会破坏操作系统运行环境,将会导致操作系统的崩溃,进而导致上层全部应用程序的崩溃,这对于计算机来说是灾难性的。 通过内核态和用户态区分,可以保护底层操作系统健壮性,保证系统安全运行,上层程序的bug不会破坏操作系统的运行环境。(当然,操作系统也可能存在bug,比如windows系统经常性蓝屏)
什么时候运行在内核态?什么时候运行在用户态?
程序大多数时间是运行在用户态,当程序需要操作系统完成协助时会从用户态切换到内核态。 需要协助的场景有: 系统调用:读取文件、网卡发起网络请求 异常:缺页、除以0等触发异常 中断处理:接收网卡数据等
用户态切换到内核态需要哪些操作?
以读取系统文件为例,操作系统提供一种接口(机制)供上层应用调用,上层应用程序在进行read系统调用时,会触发程序从用户态切换到内核态,执行完相关的系统调用后,再从内核态切换到用户态,继续执行上层应用程序的逻辑。 其大概流程如下:
- 保留用户态现场(上下文、寄存器、用户栈等)
- 复制用户态参数,用户栈切到内核栈,进入内核态
- 额外的检查(因为内核代码对用户不信任)
- 执行内核态代码
- 复制内核态代码执行结果,回到用户态
- 恢复用户态现场(上下文、寄存器、用户栈等)
结论: 从用户态切换到内核态需要“额外的”成本。
线程模型
鉴于系统用户态与内核态的存在,线程实现方式分为内核态线程和用户态线程:
内核态线程: 操作系统层面实现的线程
用户态线程:在操作系统上层应用实现的线程库。但无论如何,用户态线程如果想执行(操作系统硬件资源),都需要映射或者绑定到内核态线程。
1:1 模型
即创建一个用户态线程即创建一个内核态线程,用户态线程销毁,则内核态线程也销毁。线程不断创建与销毁,开销较大
M:1模型
用户态M个线程共用内核态一个线程,用户态线程任意一个线程阻塞,将导致内核态线程阻塞。
M:N模型
用户态M个线程映射到内核态N个线程上,如果用户态线程阻塞导致内核态线程阻塞,则可以将其他用户态线程绑定到新的内核态线程继续执行。

从0到1设计Golang协程调度器
版本v1.0.0 —— G模型
按照线程模型 1:1模型,实现调度器的1.0版核心逻辑是:
- 每次创建一个用户态线程,则同步创建一个内核态线程用于执行用户态线程。

优点
- 将线程调度交给内核完成,语言层面无需实现调度器。
缺点
- 创建成本:大量创建、销毁内核线程,导致不必要的系统开销。
- 调度成本:对于短任务(执行时间小于系统内核线程调度时间片),会持续导致内核线程上下文切换,引入不必要的系统开销。
注:C++线程库则采用这种方式
版本v2.0.0 —— GM模型
按照2.1节分析可知,每次创建/销毁内核线程,成本较大,因此是否可以池化技术,将运行结束的内核线程缓存下来,用户态线程创建后直接绑定到内核线程池中获取一个线程进行运行,从而减少创建和销毁的步骤。 因此借鉴池化思想,采用M:N线程模型实现线程调度器,其核心思路:
- 维护一个全局的任务队列,用户态每次创建线程,即放入全局任务队列中
- 池化技术创建一批内核态线程,从全局任务队列中获取用户任务执行,执行结束or执行时间片结束后再次放入队列等待下次调度。
优点:
- 解决方案一中持续创建内核线程导致的系统开销以及短任务执行导致的内核态线程不断上下文切换开销。
缺点
- 因为涉及到全局队列(临界区)的读写操作,并发操作需要进行加锁、解锁操作。
- 需要实现 用户态线程(协程)调度器
版本v3.0.0 ——PM模型
既然全局队列导致临界区的并发操作,需要加锁进行,那么是否可以每个内核线程创建一个”私有“队列,不同内核线程从”私有“队列中获取任务。上述思路可以简单理解为PM模型。
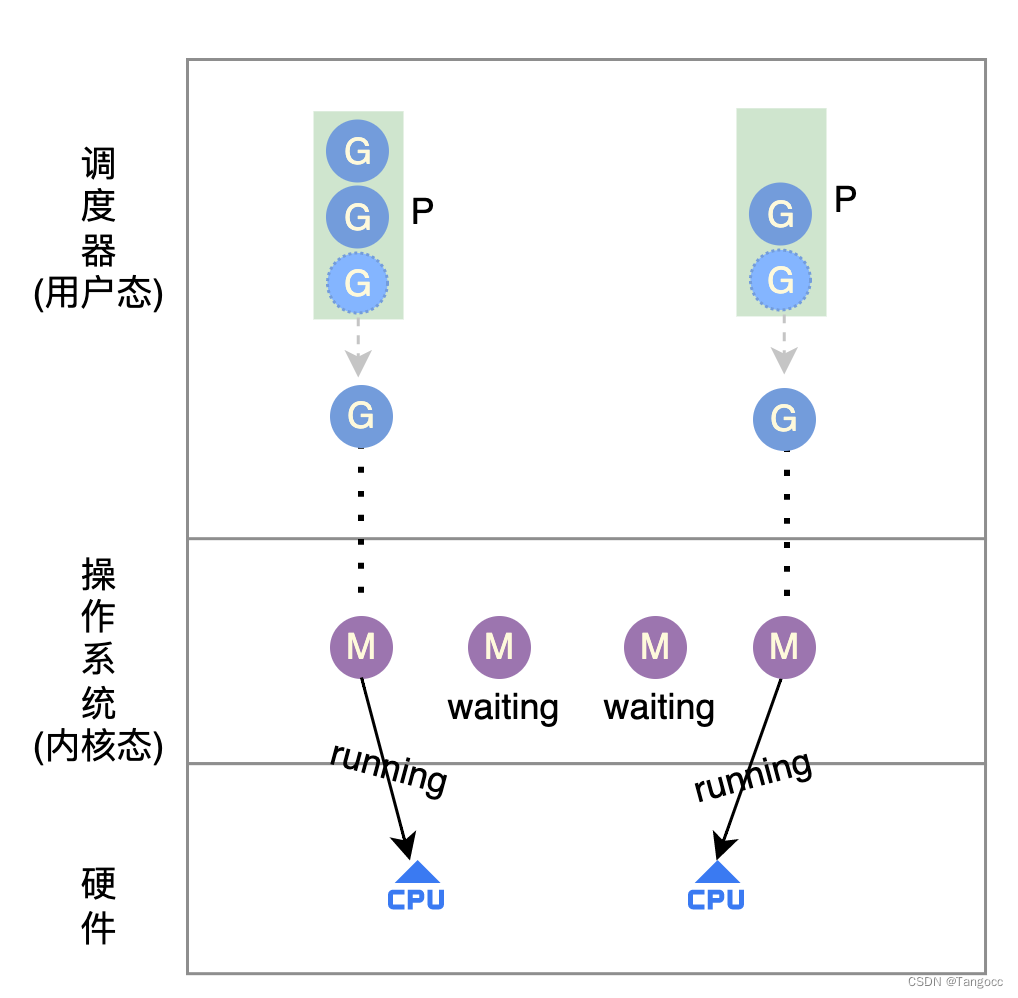
这里有两个问题:
- 每个任务的执行时间长短不一致,可能存在P1队列中任务执行结束,P2中任务还未执行完?
- 可能有同学说如果P1执行完以后,是不是可以从P2队列中“偷”一些G进行执行?
- 那么问题来了,举例只是举了2个P,如果有N个P的话,P1是不是还需要从N个P中找到一个任务较多的P进行“偷窃”
- P数量个数受限于机器核数(等于),本地队列长度有限,如果任务数过多,可能导致多个P本地队列仍然无法缓存下全部的G
- 那是否可以将本地队列大小进行扩展?
- 可以,但是我们可以假设程序在多数情况下,任务数是较小的, 极端情况下可能出现任务的暴涨,如果本地队列数过大,导致不必要的内存消耗。
挖坑1: 本地队列大小是多少?
版本v4.0.0——GPM模型
鉴于上述问题,以及GM模型中全局队列思路,进一步优化思路:
- 每个P有本地队列,然后有一个全局队列,每次构建G先尝试放入P队列,如果P队列容量不足,则放入全局队列。
- 如果P本地队列G数量为0,则尝试从全局队列中获取G执行,如果全局队列中也无可运行G,则尝试从其他P的本地队列中“偷窃”可运行的G。
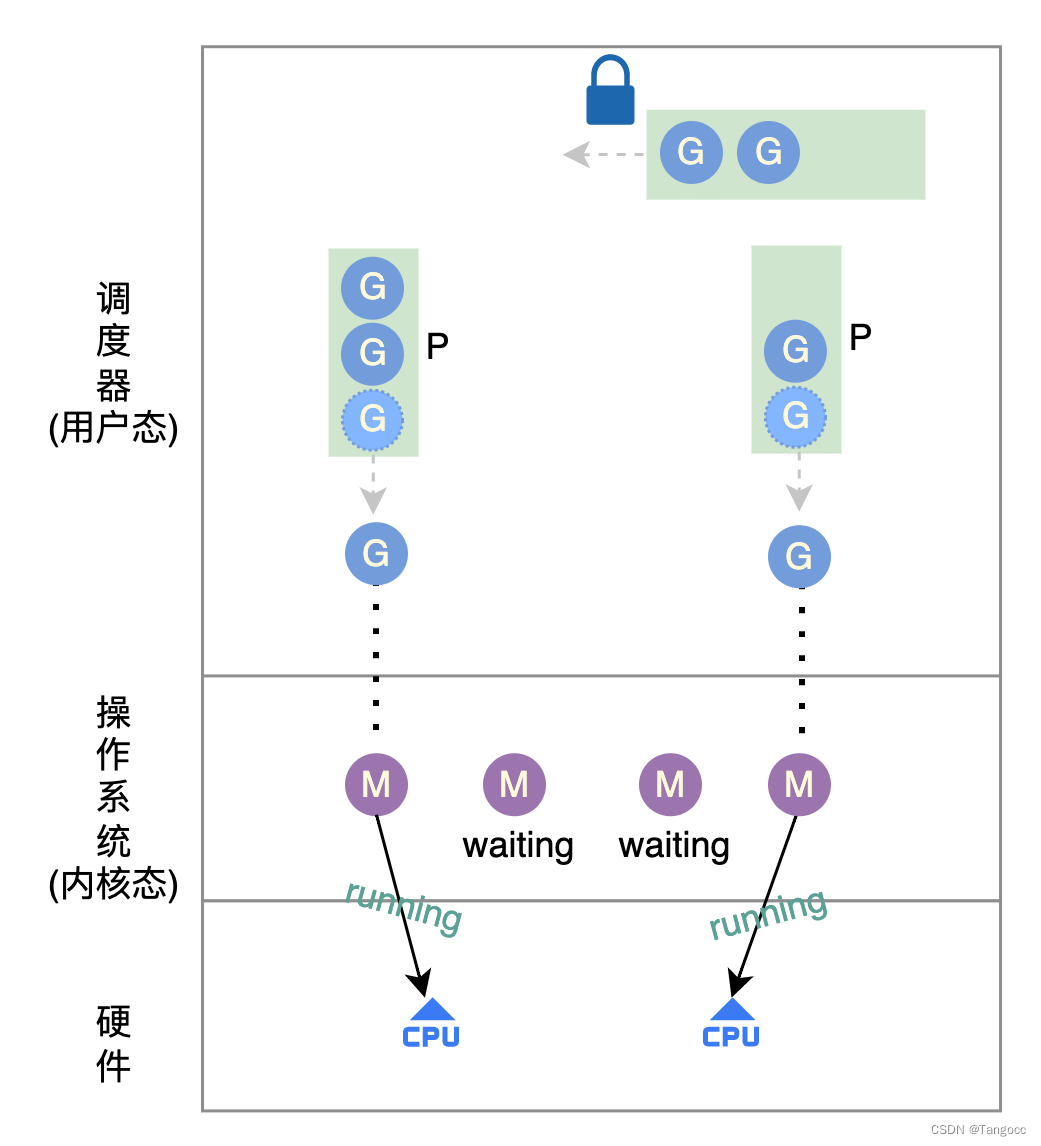
挖坑2:本地队列和全局队列如何实现的?全局队列如何实现不限制大小?
挖坑3:假设P本地队列中的任务时间都较长,且数量满负荷运行,是否会导致全局队列中的G迟迟得不到调度,出现“饥饿”状态?
挖坑4:调度器如何进行G的调度?如何内核态线程M阻塞(如socket请求)会阻塞相应P的所有G执行么?
至此,从0到1 完整“设计”出GPM模型。
填坑
- 挖坑1: 本地队列大小是多少?
type p struct {
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
// runnext, if non-nil, is a runnable G that was ready'd by
// the current G and should be run next instead of what's in
// runq if there's time remaining in the running G's time
// slice. It will inherit the time left in the current time
// slice. If a set of goroutines is locked in a
// communicate-and-wait pattern, this schedules that set as a
// unit and eliminates the (potentially large) scheduling
// latency that otherwise arises from adding the ready'd
// goroutines to the end of the run queue.
runnext
}
从p结构定义中可知,本地队列的数据结构是数组,其大小为256。
- 挖坑2:本地队列和全局队列如何实现的?全局队列如何实现不限制大小?
type schedt struct {
// Global runnable queue.
runq gQueue
runqsize int32
}
从schedt结构体定义可知,全局队列的数据结构是链表,所以其长度不受限制。 本地队列实现方式是数组,长度为256。
挖坑3:假设P本地队列中的任务时间都较长,且数量满负荷运行,是否会导致全局队列中的G迟迟得不到调度,出现“饥饿”状态?
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
深入调度代码可知,每次调度本地队列中G61次后则会尝试从全局队列中获取一部分G进行执行,这样保证全局队列的G有一定机会获取调度机会。
挖坑4:调度器如何进行G的调度?如果内核态线程M阻塞(如socket请求)会阻塞相应P的所有G执行么
- 异步系统调用 G 会和MP分离(G挂到netpoller)
- 同步系统调用 MG 会和P分离(P另寻M),当M从系统调用返回时,不会继续执行,而是将G放到run queue。
具体原理参考文章:https://qiankunli.github.io/2020/11/21/goroutine_system_call.html
总结
本文首先从操作系统内核态和用户态说起,介绍线程模型实现方式,进而引申出Golang调度器的设计,并从0-4版本设计和优化,逐步演化到GPM模型,在这过程中,介绍各种模型实现方式的优缺点,进而可以体会到GPM模型的设计理念,加深用户对GPM模型的理解。